一位谷歌资深工程师透露,Anthropic 的 Claude Code 用一小时跑出了她团队打磨了一年的系统。
1 月 2 日,谷歌主管工程师、负责 Gemini API 的 Jaana Dogan 在 X 上写道:“我们从去年开始就在谷歌内部尝试构建分布式 Agent 编排器。但可选路线很多,大家并没有完全对齐……我只是把问题用三段话描述了一下交给 Claude Code,它在一小时内就生成了一个系统,和我们去年做出来的东西非常接近。”
“我不是在开玩笑,这件事一点也不好笑。”
她补充说,这个元旦假期里自己终于第一次有时间拿一些“玩具项目”随手试一试。由于无法分享任何专有信息,提示里也不可能包含真实的内部细节,所以她只是基于一些已有思路搭了一个“玩具版”来评估 Claude Code;整个问题描述也就三段文字。
“它还不完美,我也还在不断迭代和打磨,但现实就是这样。”Dogan 写道,“如果你对编码 Agent 持怀疑态度,就把它拿到你已经非常熟悉的领域里试一试:从零开始做一个足够复杂的东西,由你亲自来判断它产出的这些‘成果物’到底靠不靠谱。”
她同时说明,在谷歌内部,Claude Code 目前只允许用于开源项目,不得用于公司内部代码。
补充一点背景是,Dogan 说自己做编程语言相关工作以来,几乎没见过开发者社区对同一件事出现如此两极化的反应。她在 1 月 3 日晚发文感叹:围绕 coding agents 的讨论里充斥着大量“炒作”和“空话”,这些噪音常常把真正扎实的工作淹没掉;她强调,事情本不必走向如此撕裂。
在她看来,行业整体仍处在一个“可以视为全行业研究项目”的阶段:语言模型还在被探索、还会持续变强;团队会在看到价值的地方逐步把它“产品化 / 工程化”,同时也借此推动更多探索。
她甚至回忆说,三四年前自己一度考虑过退休——那时她感觉行业“过度饱和”,似乎已经没什么实质性的新东西可做:无论是作业调度器、网络接口,还是各种基础设施,大家都在反复“重造已被造过的轮子”,却只是在制造更多复杂度。
正因如此,她反而喜欢上这波 AI 编程浪潮带来的“新岔路”:它让像她这样的工程师重新有了新鲜的问题可以研究。只是 LLM 变得过于“迅速且广泛可得”,也随之引发了更强烈的情绪化反应;她怀念更早些年——当时只有一小群人带着好奇心去探索新模型的阶段。
Dogan 还总结了 AI 编程能力的快速跃迁:
- 2022 年:只能补全单行代码
- 2023 年:可以生成完整代码片段
- 2024 年:可跨多个文件工作,构建简单应用
- 2025 年:能够创建并重构整个代码库
她写道:
“在 2022 年时,我根本不相信 2024 年的里程碑能作为一个面向全球开发者的产品真正落地。这个领域在质量和效率上的提升,已经远远超出了任何人的想象。”
也有同行从另一个角度补了一句“体感”。前谷歌、Meta 杰出工程师、Gemini 共同作者 @arohan 写道:他自己也曾是谷歌工程师,一路升级打怪;如果当年就能用上 agentic coding,尤其是 Opus 这样的模型,他可能会把职业生涯最初 6 年 的积累压缩到短短几个月。
更重要的是,他认为“能直接把事情做出来”还有一个副作用:人会保持锋利。技能不会自动维持不变,不用就会退化;而具备自主性的 agentic coding,本质上是一种“反萎缩机制”——你持续在做判断、做执行,就不容易变钝。
Dogan 身为谷歌工程师,却公开高度评价了一款竞争对手的产品。这无疑给大家带来了巨大震撼,也带来了一些争议。
毕竟她并不是一位“普通工程师”。有网友指出,作为谷歌的主管工程师,她在以“实操落地”为导向的工程岗位体系里几乎处在“金字塔尖”:这类角色往往要负责设计并推动落地面向全球规模的系统与基础设施。也正因如此,这条推文才会引发如此高的关注;而她又参与 Gemini 相关工作,更让外界对这番公开表态格外敏感。
也有人认为,正因为她的身份分量够重,这番表态甚至可能被视为某种“技术转折点”的信号。
围绕这条分享,讨论也迅速延伸到了 “一年工程 vs 一小时生成”背后真正被压缩的是什么。
也有人用明显的讽刺口吻表达怀疑:每当有人说“AI 一小时做完我们一年做的事”,真实情况往往是——人类花了一年把最难的“思考”和“定义问题”做完了,AI 只是以硅的速度把这些内容复述出来,这和“生产力提升”完全不是一回事。
如果一个团队真的要花一年,更多反映的是流程问题,而不是 AI 有多强。在他看来,写代码反而是最容易的部分,真正消耗时间的是会议、对齐、架构争论、Jira 梳理,以及在 snake_case 和 camelCase 之间反复纠结——Claude 并没有做这些,所以“它其实什么也没做”。
他还继续自嘲:自己花了多年培养直觉、判断和品味,这些原本以为无法被自动化,结果却被一个“概率文本模型”在自己坚持称之为“微妙”的领域里不断超越;当然,输出能跑、能过测试、能替代数月努力,但它“不理解自己在做什么”——不像他本人,“绝对理解”自己从 Stack Overflow 复制的每一行代码。最后他用一句话收束:“如果 AI 真那么强,它早就让我失业了;既然我还有工作,那这一切肯定都是炒作。”
有网友向 Dogan 抛出了一个关键问题(截至目前她尚未回应):过去这一年的工作里,究竟有多少时间花在把问题的规格与边界定义清楚,而不是实际的执行与编码?
在他看来,这才是核心所在——一旦你能够把问题完整描述出来,并且能聪明地引导执行者避开所有潜在陷阱,很多工作都可以在极短时间内完成。他分享了自己的经验:自己和同事曾在一夜之间重写过代码库中的大块内容,但真正花了好几年的,是找到“正确解法”本身;一旦解法确定,编码往往只需要几个小时,在现代工具的加持下甚至更快。
也有人感慨,“一年工作一小时做完”当然令人震惊,但它同时暴露了一个长期被忽视的现实:大量开发时间并不是被写代码本身消耗掉的,而是被会议、规划、调试以及频繁的上下文切换吞噬。AI 的作用,恰恰是在这些噪音之上直接“切一刀”。
他也因此表达担忧:企业看到这种效率提升后,可能首先想到的是削减人力,而不是把工程师重新配置到更高层次的工作上。
还有评论从更日常的角度补了一刀:几乎每天早上八点左右,他都会想着“今天一定能干成不少事”,结果一抬头已经两三点了,发现脑子里还是同样的想法——工作中充斥着大量毫无必要的会议,简直让人抓狂。
而面对巨大争议,一天后 Dogan 又单独发了一条推文强调:“做出第一个版本,不等于做成一个产品”,希望以此为这场争论画上句号。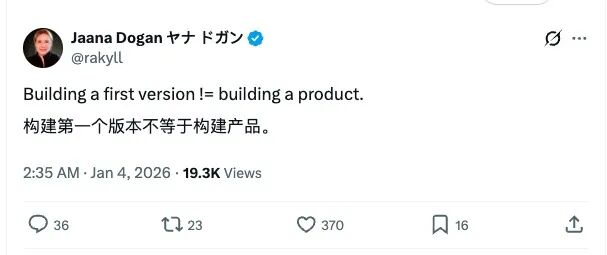
当有人询问谷歌的 Gemini 何时能达到类似能力时,Dogan 回应称,她的团队目前正在“全力推进模型和基础设施建设”。
另一个容易被忽视的背景是:谷歌其实也是 Anthropic 的重要投资方之一。有评论提到,谷歌目前持有 Anthropic 约 14% 的股份;也有网友称,谷歌内部长期在使用 Sonnet 和 Opus,并表示自己曾在 DeepMind 的内部网络环境中验证过这一点。还有人则指出,以谷歌的体量和布局,本就可能同时为多条技术路线“背书”。

在资本与算力层面,谷歌与 Anthropic 的绑定更为直接:谷歌累计投资 Anthropic 约 30 亿美元。双方在 2025 年 10 月进一步深化合作——谷歌同意向 Anthropic 提供最多 100 万颗 TPU(张量处理单元),交易总价值高达数百亿美元。
该协议预计将在 2026 年带来超过 1 吉瓦的算力上线,成为 AI 行业历史上规模最大的硬件承诺之一。Anthropic 表示,选择谷歌 TPU 的原因包括更优的成本效率、稳定的性能,以及谷歌在该处理器上的长期经验。
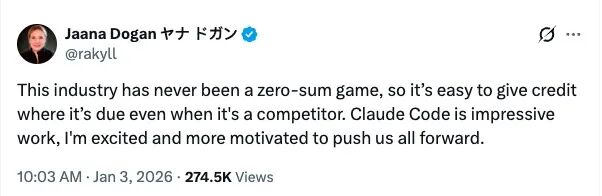
Dogan 对此写道:
“这个行业从来不是零和博弈。即便对方是竞争对手,也完全可以坦然承认他们做得出色。Claude Code 的工作令人印象深刻,它让我更加兴奋,也更有动力继续向前。”
Anthropic 的 Claude Code 创建者 Boris Cherny 也在 2025 年 12 月下旬披露:在此前 30 天里,他对 Claude Code 项目的所有贡献——共 259 个 Pull Request、497 次提交,累计 新增约 4 万行代码、删除约 3.8 万行代码——“每一行都由 Claude Code 搭配 Opus 4.5 完成”。那一个月里,他甚至一次 IDE 都没有打开过。
几乎在假期里的同一时间,Cherny 还系统总结了自己的工作流“秘籍”。他给出的首要建议是:一定要让 Claude 有办法验证自己的工作——只要建立起稳定的反馈回路,最终产出质量往往能提升 2~3 倍。
具体做法上,他建议多数任务先从 Plan 模式开始,先把计划推敲扎实;计划一旦确定,Claude 往往就能“一把梭”完成实现。对高频重复的操作,他会用 slash commands 和子 agent 固化成可复用流程,比如自动做代码简化、端到端测试等。面对更长周期的任务,他会运行后台 agent 在完成后复查输出,并行开多个 Claude 实例分工推进;代码评审时,团队甚至会直接在同事的 PR 里 @Claude 来补充文档或规则说明。按他的说法,Claude Code 也能接入 Slack、BigQuery、Sentry 等外部工具,把“写代码”嵌入到更完整的工程流程里。
而 Cherny 在推文中分享的这套“用法”,很快也被 Dogan 注意到。她转发之后不久,便发布了那条引发巨大争议的动态——把 Claude Code 一小时生成原型、对照谷歌团队一年推进的经历,推到了聚光灯下。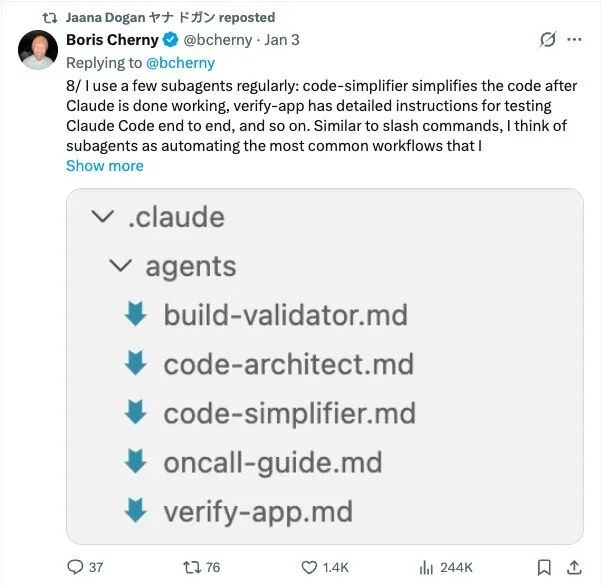
相关文章
