光正在进入AI算力系统,但这次不只是拿来传数据,而是直接参与计算。
华中科技大学与上海交通大学团队最新在Nature Communications上发表成果,将可编程光子神经网络写入玻璃内部,构建出一个三维光学计算核心。

该芯片实现了二维图像的直接片上光学处理——
MNIST手写数字分类准确率达93%,片上光学图案生成保真度94%,理论计算吞吐量达到6554 TOPS。
其关键架构路径是:
二维空间输入→三维光场混合→可编程相位调控→片上神经网络推理。
这不仅是把光学矩阵做大,更是回答了一个核心问题——光学计算核心如何做大、可编程,并承载真实数据。
把光子神经网络写进玻璃三维空间
过去几年,随着AI集群规模持续扩大,产业界谈到光,更多是在谈光互连:用光连接芯片、板卡、机柜和数据中心,让数据以更高带宽、更低功耗传输。
这个方向已经成为AI硬件里非常明确的技术趋势。
但光的价值不止于“传数据”。
光在传播过程中可以复用、耦合、干涉和混合;在很多线性计算中,这些物理过程本身就可以成为计算过程。
对于AI推理中大量存在的矩阵计算来说,光不仅可以是连接计算单元的媒介,也可能成为计算核心的一部分。
真正困难的是:什么样的光学计算核心,才能把这种优势放大?
光计算系统需要激光器、调制器、探测器、电控和封装。如果规模太小,这些外围开销很难被摊薄;如果结构仍然局限在二维平面,输入、互连、波导交叉和通道扩展又会限制芯片规模。
也就是说,光计算要真正走向AI推理硬件,不能只证明“光能算”,还要回答“光学计算核心如何做大、如何可编程、如何承载真实数据”。
2023年, Peter McMahon在Nature期刊发表了一篇综述。
文章系统梳理了光可用于计算的多种物理特性,也指出光计算的优势并不是简单来自“光速快”,而是要靠架构设计同时调用多种光学自由度。
这篇综述引出了一个更具体的问题:现有光计算芯片到底利用了光的哪些优势?又有哪些自由度还没有被真正打开?
这就是这项工作的起点。
基于这个思路,华中科技大学张新亮、董建绩团队联合上海交通大学唐豪、徐晓芸团队,把可编程光子神经网络写入玻璃内部,构建一个三维光学计算核心。
相关工作以Programmable Three-dimensional Photonic Neural Network Chip为题发表于Nature Communications。
这块芯片实现了二维图像的直接片上光学处理:MNIST手写数字分类准确率达到93%,片上光学图案生成保真度达到94%,理论计算吞吐量达到6554 TOPS。
这项工作的核心,不是把一个光学矩阵做得更大一点,而是验证一条新的架构链条:
二维空间输入→三维光场混合→可编程相位调控→片上神经网络推理。
现有方案卡在哪里
光子神经网络已经研究了三十多年。
近年来,硅光子、薄膜铌酸锂、氮化硅等平面平台上出现了大量优秀工作,学界和产业界对“光可以做矩阵运算”这件事,早已有共识。
但如果光计算要真正走向大规模AI推理,不能只停留在一个小型光学单元里。
它必须回答一个更系统的问题:数据如何进入芯片?通道如何扩展?互连如何组织?光的多维自由度如何转化为可训练、可制造、可扩展的计算架构?
平面2D结构在规模扩展时,会遇到三个很直接的问题。
问题1:输入维度的限制
真实世界的数据——图像、视频帧、传感阵列——天然具有二维甚至更高维的空间结构。但很多平面光子芯片的输入接口本质上仍然是一组有限的片上通道。
为了把一幅二维图像送入芯片,数据往往需要先被展开、复用或串行化,再进入计算核心。
这有点像把一幅画卷成一条线,再塞进管道。问题不只是输入速度变慢,更重要的是,数据原本具有的空间邻域关系和并行结构,在进入芯片之前就被重排了。
光本可以直接利用空间通道并行处理信息,但平面输入方式会先把这种优势压缩掉。
问题2:片上互连的限制
数据进入芯片之后,光信号还需要在不同计算单元之间传播、耦合和混合。
对于小规模器件来说,这件事不难;但当通道数增加,二维平面上的波导排布会迅速变得拥挤。
在平面芯片中,许多连接关系必须在同一层中绕行或交叉。绕行会增加路径长度和损耗,交叉会带来串扰和额外插入损耗。矩阵规模越大,互连关系越复杂,这些问题越难避免。
换句话说,平面结构不是不能做光计算,而是当连接关系变得密集时,二维空间本身开始变成约束。
问题3:规模扩展的限制
光计算真正可能发挥优势的地方,是大规模并行线性计算。
可是要把规模继续做大,不能只增加计算单元,还要同时增加输入输出通道、调控单元、读出端口和封装接口。
在二维平面上,这些资源都会竞争同一块芯片面积。
输入输出要占边界,调制器和电极要占表面,波导要占路由空间,探测和读出也需要接口。随着规模增加,限制不再来自某一个器件,而是来自整个平面系统的拥挤。
因此,平面结构的问题不是某一个环节“不够好”,而是输入、互连、调控和封装都被压在同一个二维空间里。规模越大,这种几何约束越明显。
这三个问题背后,其实指向同一个事实:
很多光子芯片仍然在用二维平面的方式组织光,而光本来可以在三维空间中传播、耦合和重构。
这里还涉及一个更深的问题:为什么三维对光可能比对电子更自然?
电子计算当然也在走向三维,比如HBM、chiplet、TSV和先进封装。但电子的三维扩展,更多是在缓解计算、存储和互连之间的距离问题。
即使进入三维,电互连仍然要面对电阻、电容、充放电、热管理和同步复杂度。高密度堆叠可以缩短部分路径,但不会消除这些基本代价。
光面对的是另一组约束。它并不是没有工程挑战,但在透明介质中,光信号可以通过三维空间路由、模式耦合和多通道并行来组织信息,而不需要像电互连那样依赖大规模导线充放电。
这就是三维光计算相对于二维平面光子芯片、也相对于传统电互连架构的不同之处。
但三维光学系统长期以来也有自己的问题:自由空间光学体积庞大、对准困难、环境敏感,很难成为真正的芯片级系统。
这项工作的核心,正是在这里:
在保持芯片级集成的前提下,把三维空间自由度真正引入光子计算。
这两件事以前被认为难以兼得。
为什么是玻璃,为什么是三维
与产业界将玻璃主要用于先进封装中的电互连不同,这项研究工作将玻璃本身变成了计算发生的空间——
光在玻璃内部传播、耦合与重新分布的过程,直接承担了线性计算功能。
这一思路与CPO、光电集成等方向背后的系统逻辑一脉相承:封装承担的系统功能边界正在扩展,而这项工作提供了玻璃从互连平台进一步延伸出计算能力的早期原型验证。
飞秒激光直写技术可以把超短脉冲激光聚焦到透明玻璃内部,在焦点附近局部改变折射率,从而在材料内部写入光波导,如同在玻璃内部直接刻画出光的三维轨道。
传统平面光子芯片是在一张纸上画光路;这块芯片,是把这张纸变成一块透明体积。
光不再只能沿着表面绕行,而可以在不同深度之间传播、耦合和重构。因此,该工作的意义,不只是材料换了,而是计算核心的几何组织方式变了。
研究团队具体做了什么
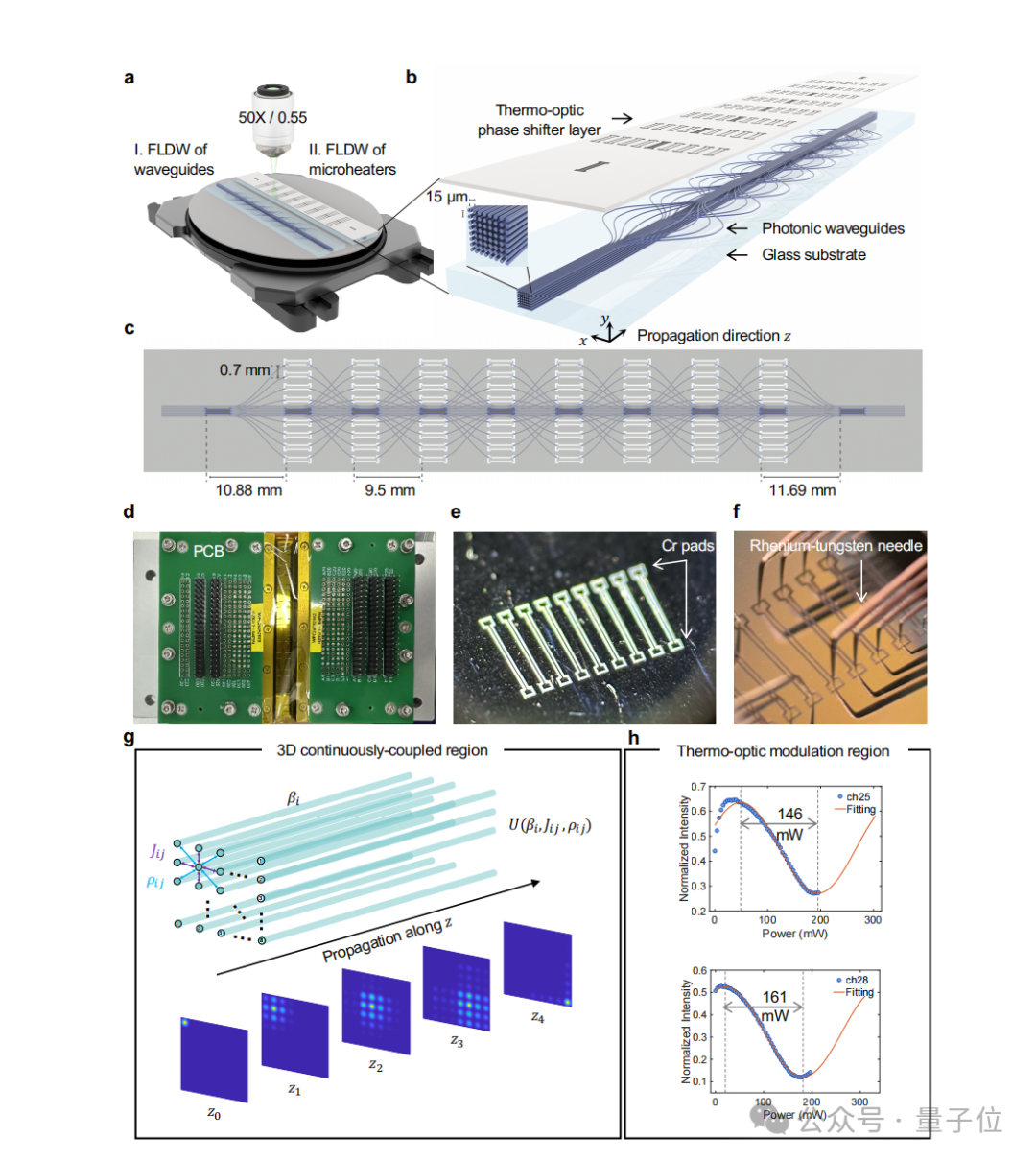
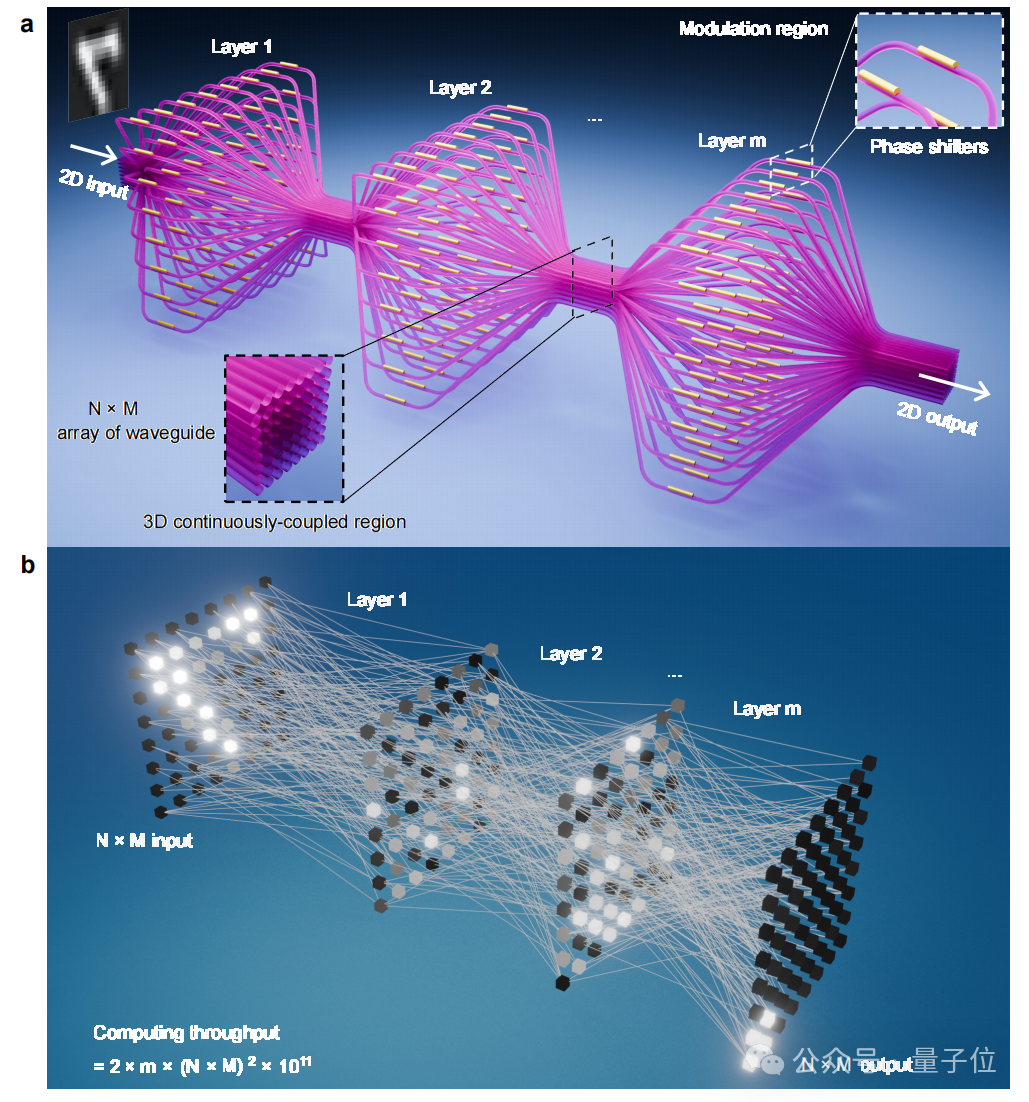
芯片的核心架构由三维光子灯笼波导阵列与可编程相移器阵列交替级联构成,共包含8个级联层级,实现了8×8二维阵列输入输出规模的三维光学网络。
这里有两个关键模块:三维光子灯笼和相移器阵列。
三维光子灯笼的作用,是让光在玻璃内部的体积空间中发生多通道传播、耦合和重新分布。
它并不是一个简单的功率分束器,不是把一路光机械地平均分成几路;
更准确地说,它通过三维波导之间的连续耦合,使输入光场在多个空间通道之间发生混合,从而形成一个多端口的线性光学变换。
从神经网络角度看,这个过程相当于用光的传播和耦合完成矩阵运算中的线性混合。不同的是,这里的连接关系不是主要依赖平面内波导路由实现,而是通过玻璃内部的三维波导排布和耦合关系形成。
相移器阵列则负责让这个线性网络变得可编程。
通过调节不同通道中的光学相位,芯片的整体传输响应会随之改变。也就是说,同一块芯片可以通过外部训练和电控调节适配不同任务,而不需要为每一个任务重新制造一块芯片。
在这套架构中,这两个模块的作用是互补的:三维光子灯笼提供复杂的空间混合,相移器阵列提供可编程调控。
交替级联之后,三维混合提供“计算空间”,相位调控提供“训练自由度”,二者共同构成一个可训练的三维光子神经网络。
级联的每一层都可以看作一次“混合—调控”的计算步骤:光先在三维灯笼结构中发生耦合和重分布,再经过相移器阵列进行可编程调节,然后进入下一层继续传播和混合。
多层级联后,芯片能够实现更丰富的线性变换。
用一个更直观的方式理解:这块原型芯片并不是让光在单个平面里走一遍,而是让64路并行输入在玻璃内部经过多轮三维混合和相位调节。每一轮都会改变光场在空间中的分布,最终在输出端形成与任务相关的光学响应。
更重要的是,它可以以二维阵列形式接收图像信息。
在实验中,二维图像信息被编码到输入光场中,并耦合进入输入波导阵列。也就是说,图像信息不需要以一维串行通道逐点送入芯片,而是可以被编码为二维空间阵列后进入三维光学网络。
对于图像、传感阵列、空间光场这类天然具有二维结构的数据,这一点非常关键。
这也是这项工作与许多平面光子神经网络不同的地方:它不仅在芯片内部使用三维结构,也在输入方式上尽量保留了二维数据本身的空间并行性。
总结起来,这块芯片的架构逻辑可以概括为:输入端保留二维空间结构,芯片内部调用三维传播和耦合,相移器提供可训练自由度,输出端完成片上光学推理。
这就是“把光子神经网络写进玻璃三维空间”的具体含义。
架构是否真的有效
这种架构是否真的有效,论文中通过多个实验和分析进行了验证。
在MNIST手写数字分类任务中,芯片实现了93%的分类准确率。
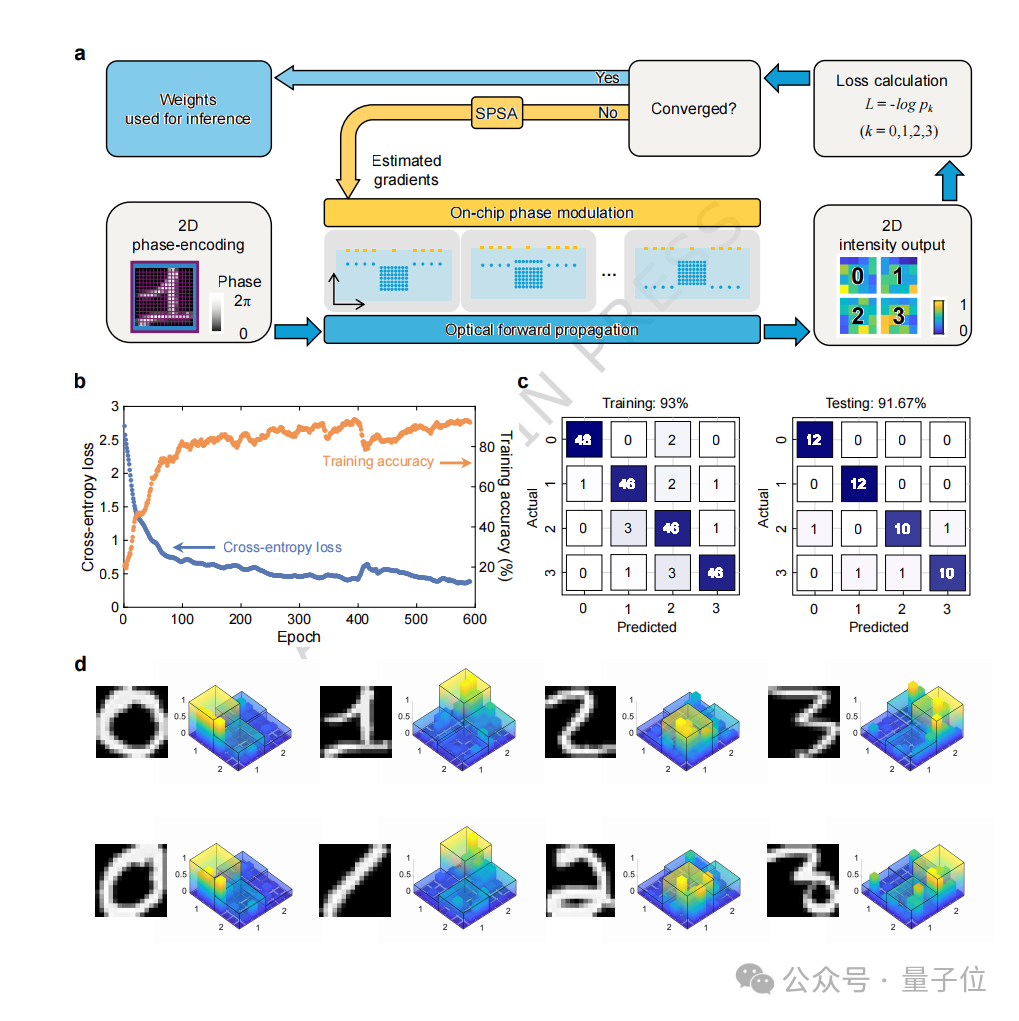
这个结果的重点不是与成熟电子神经网络的软件精度直接竞争,而是说明二维图像可以被编码进入输入阵列,并在三维光子网络中完成从光场传播、可编程调控到分类读出的完整闭环。
研究团队还展示了片上光学图案生成,输出光场与目标图案之间的相似度达到94%。
这一结果说明,三维光子灯笼带来的复杂混合并非不可调控,而是可以通过相位训练被引导到特定的输出分布。
换句话说,芯片不仅能让光复杂地混合,也能让这种混合服务于目标任务。
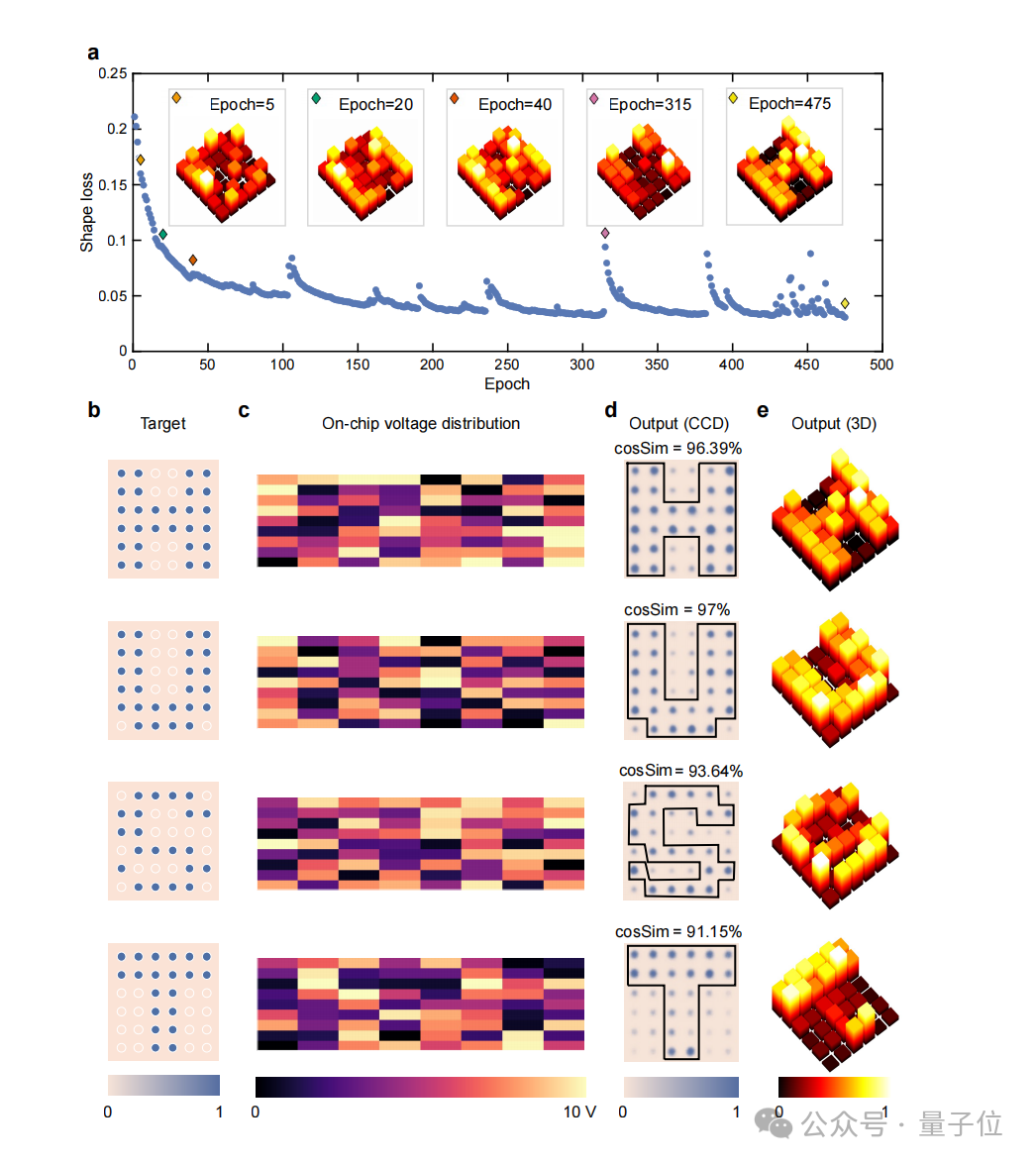
此外,论文按照其定义的计算吞吐量估算方法,给出了6554 TOPS的光学核心等效计算吞吐量。
这个数字不应被理解为包含激光器、调制器、探测器、电控和封装之后的端到端系统实测性能,而是用于表征该三维光学计算核心在并行线性运算中的规模潜力。
除了任务演示,论文补充信息中还从线性变换能力的角度分析了三维结构的优势。
通过比较不同结构的奇异值谱,研究团队发现三维网络的奇异值衰减更慢。
这一结果支持了一个判断:三维结构引入深度方向的空间自由度后,可以形成比平面结构更丰富的光场混合关系。
也正因如此,这项工作强调的不是“多做几根波导”,而是把光子神经网络的计算空间从平面扩展到体积。
这项工作的真正意义
因此,这一代原型芯片的重点,不是在第一步就把通道数做到极限,而是证明三维光子神经网络这条架构链条可以在芯片尺度上闭环。
从AI硬件角度看,规模扩展的意义不只是把算力数字做大,也在于让一次输入的数据参与更多计算。
典型电子AI加速器会通过大阵列、片上缓存和矩阵分块,让搬入芯片的数据被反复使用,从而摊薄数据搬运成本。
三维光子网络的逻辑并不相同,但目标相似:当光学计算核心足够大,一次输入的光场可以在更多通道中同时传播、耦合和混合,触发更多并行线性运算。
换句话说,它不是简单减少某一次数据搬运,而是让每一次数据注入“算得更多”。
因此64通道不是终点,而是一个可工作的起点。
研究团队已经在推进下一代上千通道I/O的三维光子集成芯片,并已进入加工阶段。
它要回答的问题是:当规模继续放大,三维空间能否比传统平面结构更有效地组织互连,真降低交叉、串扰和布线压力,进一步释放光计算在大规模并行任务中的优势。
所以,这篇论文解决的是“这条架构能不能工作”;下一代芯片要回答的是”这条架构能不能真正放大”。
光计算的下一阶段竞争,不会只发生在单个器件指标上,而会发生在架构、数据流和制造路径的重构上。
下一代光计算芯片,也许不一定只是在平面上“画”出来的。
它也可以是在玻璃里“写”出来的。
业内的技术探索
在利用玻璃来实现光计算并最终落地到芯片上,业界已经有公司在布局相关的工艺与平台。
在今年年初光本位科技宣布正在用玻璃代替硅作为衬底来研制玻璃光计算芯片。
尽管与论文中直接在玻璃中实现三维结构有所差异,但是同样在玻璃平台上提供了三维集成的完整方案,通过单层玻璃芯片堆叠的方式最终实现相同的三维输入效果。
更进一步的,光本位科技还将独有的相变材料存算一体光计算方案引入玻璃光计算芯片中,利用相变材料的非易失性,能够避免在玻璃中引入额外的相移器,从而实现计算过程几乎不耗能的三维光子神经网络系统。
如何让光学系统更加高效的完成大规模AI模型推理?
在以往常规的光子芯片上,受限于计算规模,运行一个模型往往需要多次光电转换,这会降低光子神经网络芯片在实际应用时的算力、能效比等优势。
之所以在结构、材料与制造上不断寻求突破,终级目标是将玻璃光计算芯片直接封装为超高性能全光计算系统。
全光计算系统是什么?即让光信号在光域内部实现反复计算与动态暂存,改变光计算只能作为“单个计算核心”的现状,令玻璃光计算芯片成为直接运行完整模型的AI计算平台。
对比传统全光计算的两种思路,玻璃方案的优势堪称碾压:
它既解决了三五族平台器件密度不足的问题,又突破了固定场景的应用限制,相变材料的引入,使得芯片在推理过程中保持极高能效比的同时芯片参数仍然可根据不同模型实时调整,适配性更强。
同时,玻璃的低翘曲率、低热膨胀系数特性,能轻松集成不同平台芯片,满足全光计算的复杂需求。
因此,光本位科技推出的玻璃光计算方案以及平台,为光在三维芯片中计算提供了基础。
同时也证明了三维光计算是未来的方向,玻璃光计算将改变当今光计算产品的“电主光辅”架构,形成“光电融合,以光为主”甚至“全光”的计算集群架构。
试想一下当我们发出一个AI推理请求时,不再需要将模型数据不断地从存储搬到计算单元完成计算,而是光学信号在整个玻璃体中跑过一遍就能够输出想要的结果时,AI推理的格局将发生翻天覆地的变化。
写在最后
从2023年底构想这个方向,到芯片制造、实验验证、论文发表,将近两年半。
团队的判断是:光计算最大的潜力,藏在第三个维度里。
现有方案大多已经证明光能算——但光本来可以在三维空间中传播、耦合和重构,这件事还远没有被系统地转化为架构。
芯片级集成与三维空间自由度,这两件事以前被认为难以兼得。
而这项工作想做的,正是让它们同时成立。
相关文章
