连马斯克、Andrej Karpathy 都纷纷点赞,DeepSeek 和 Kimi 前后脚都盯上的 “残差连接”,到底是什么?
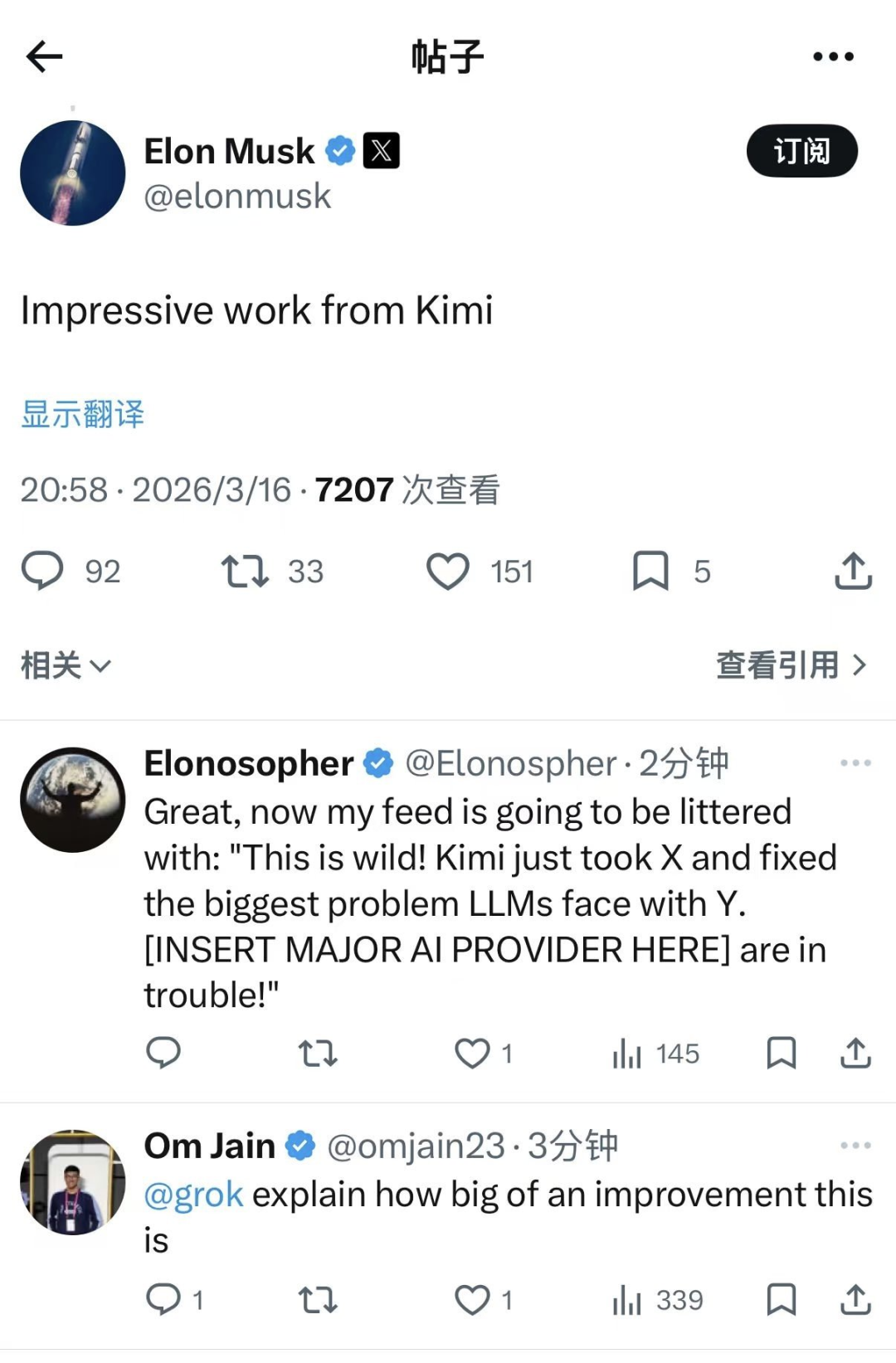
最近,Kimi 放出一篇重磅新论文,瞄准一个过去十年几乎没人动过的 Transformer 底层根基:残差连接(Residual Connection)。残差连接由何恺明于 2015 年在 ResNet 论文中提出,此后便成为深度学习领域的标配。
简单来说,可以把大模型的 Transformer 架构,想象成一支几十人排成长队的“传话小组”,那么残差连接就像一条规定:每个工人听完前面所有人的话后,都往里面再补一句,然后原封不动往后传。
这套规则长这样:
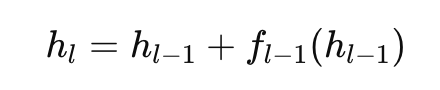
但这会带来一个麻烦:队尾的工人收到的话,是前面几十个工人的内容全堆在一起的,越往后话越乱、越长,前面工人说的重点被埋住了,后面工人加的内容也没人听得清,AI 就变笨了。这叫“稀释问题”。
于是,Kimi 想到把 “注意力机制” 引进来解决这一问题,它提出一个新的规则:“注意力残差”(Attention Residuals)。如同给工人们配备了“智能筛选器”,不用再全盘收下前面堆出来的大杂烩,可以选择重点听前面自己关心的内容。
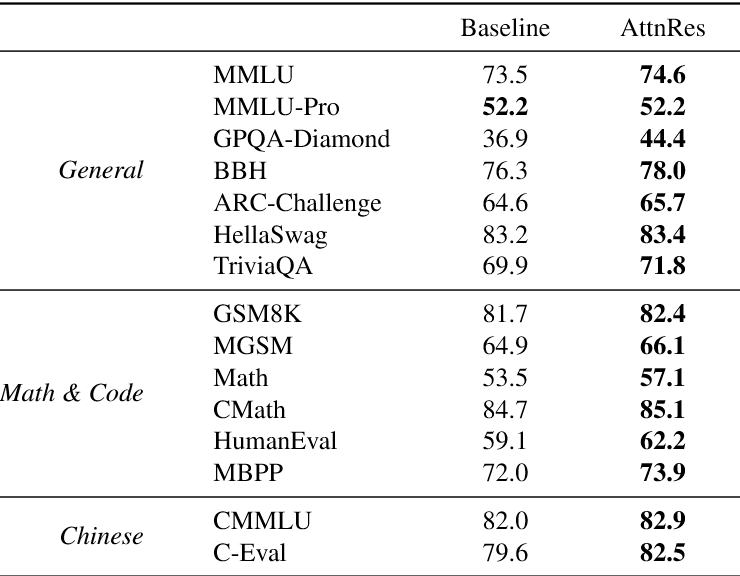
结果,AI 变得更聪明了。不仅实现了全场景的稳定提升,在研究生级专业考试、高等数学推理、代码生成、超长文本理解这类真正考验 AI 硬实力的高难度任务上,更是直接实现了 3-7.5 个点的暴涨。
而且更省钱了。在 Kimi 自家的大模型架构上验证显示可以节约 1.25 倍算力, 而训练端到端额外开销 不到 4%, 推理延迟增加不到 2%,基本没什么额外负担。
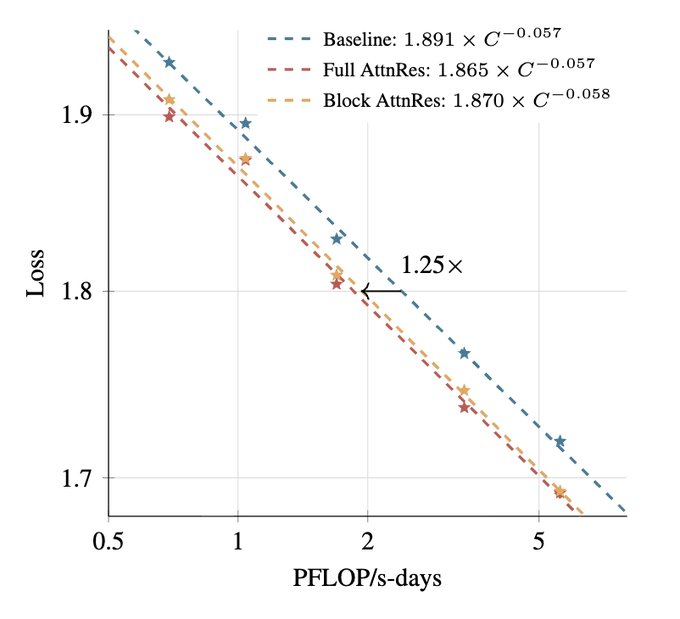
而且它完全适配大模型的缩放定律,模型规模越大,这套规则的优势越明显。
残差连接之所以能存在这么久,是因为它为 AI 信息的流动开了一条“主干道”,把教 AI 的纠错信号一路传下去,从而让深层网络更容易训练,不会把前面的好东西丢掉。
但这有三个致命问题改不了,分别是:
- 不能挑着听:不管是负责“抓重点”的工人,还是负责“整理内容”的工人,都只能听前面堆成一团的话,不能自己选听谁的
- 丢了的内容找不回来:前面工人说的重点,一旦被后面的内容盖住,就再也挖不出来了,AI 聊着聊着就忘了您最开始说的话
- 内容越堆越多:越往后的工人,必须扯着嗓子喊、加更多内容,才能让队尾听到,不然就被前面的内容盖住了,教 AI 的时候很容易教乱套
之前也有不少人想要改善这些顽疾,比如 PreNorm 这种,只是调整内容整理的顺序,完全不改变残差的固定累加规则,完全没改到根子上;或者 MRLA 这类,确实动了规则,但设计太复杂,AI 根本跑不动。
而 Kimi 的灵感,来自于他们发现,“序列维度上的时间问题和深度维度上的曾问题,本质是同一件事”。
当年 AI 读长句子,只能一个词一个词往后传,前面的内容记不住,后来发明了注意力机制,让 AI 能自己选句子里哪个词重要,一下子就解决了。而这和“工人队伍里传话的先后顺序”,本质上是一样的。
注意力残差链接的具体做法就是:
1. 每个工人,都能直接听到前面所有工人的原声,还能打分,分数高就多听,分数低就少听,最后把所有话按分数合起来,再自己加工,传给下一个人
2. 打分是不固定的:处理数学题的时候,就多听负责逻辑的工人的话;处理聊天的时候,就多听负责语气的工人的话,特别灵活。
而公式也变成了这样,其中α就是前面所说,智能筛选器给前面每个工人打的“重要性分数”。
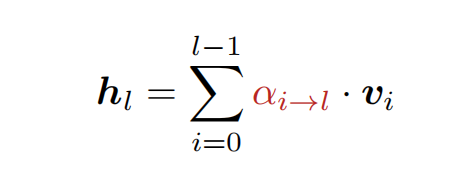
为了让这一套机制真正落地,Kimi 推出了“省力好用版”的注意力残差 ,即“分块注意力残差”(Block AttnRes)。
它会把工人分成几个小组,每个小组内部用标准残差连接做累加,类似于“小组总结”,而组与组之间再用 Attention 来做选择性收听。这样一来,大大节省了成本开支。
为了进一步优化成本,Kimi 团队还做了两项针对性优化:
-
面向训练过程的 “跨阶段缓存”:已经传过的旧内容直接存在本地不用反复来回发,每次只传新生成的内容,大幅节省算力、提升训练效率。 -
面向推理过程的 “两阶段计算策略”:将 AI 生成回复前,先把要用到的历史内容一次性找齐,再一步步算结果,不用每算一个字都重新翻一遍历史,响应更快,用户几乎感知不到任何延迟。
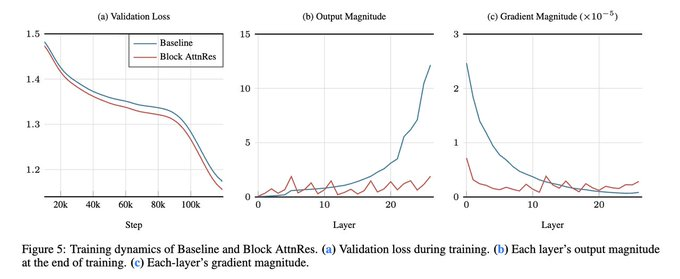
最后,Kimi 实际测试了 5 种不同大小的 AI,从 194M 到 528M,分对比了传统残差连接、注意力残差连接和分块注意力残差的实际效果。
结果发现:
-
不管 AI 是大是小,注意力残差连接都比传统残差连接犯错更少、更聪明 -
分块注意力残差连接,花同样的钱,能达到传统残差连接 1.25 倍算力才能达到的效果 -
AI 规模越大,分块版和完整无损版的注意力残差连接效果越接近,超大 AI 里,两者几乎一模一样

Kimi 还做了一系列消融实验,证明注意力残差连接中的每个设计,都必不可少:
-
必须用“随内容变的打分”,如果用固定的分数,效果就很差,甚至不如传统残差连接 -
必须用 softmax 打分,不然 AI 就不会果断选重点,效果变差 -
必须先把内容整理通顺再打分,不然信息容易盖住其他人,效果变差 -
分成 8 个左右的小组,效果最好
Kimi 的新设计给了 OpenAI 大神 Andrej Karpathy 不少启发,他忍不住深思,“注意力机制”是不是可以运用到更多的地方去?
有网友直接指出,或许 Transformer 中不少“长期沿用的配置”,都可以动一动了。

还有网友激动地将 Kimi 奉为“新的 DeepSeek”。

解法有什么不同?
虽然都是对残差连接进行创新,但 DeepSeek 推出的 mHC 却和 Kimi 的 AttnRes 走出了两条路。
如果把残差连接理解成 AI 内部的一套“传话机制”,那两家的分歧,首先来自于它们对“问题到底出在哪”的判断不同。
DeepSeek 的思路是,信息主干道太挤,信息才会乱,那就拓宽多条并行专线,用学习好的规则在专线之间混合、传递。
Kimi 的思路则是,信息主干道不能挑重点才会乱,那就给筛选权。
这也带来了两者在能力边界上的关键差别,DeepSeek 的做法只能听到 “混合后的二手内容”,听不到原版原话,而 Kimi 的做法能直接听到 “所有前面的原版原话”,想找谁的就找谁的。
两者都能提升基础效果,但擅长的领域完全不同,差距主要在复杂任务上。
-
mHC:主打 “训练稳定性”,基础能力有提升,复杂任务乏力
它的核心价值是能把模型做的更深,训练的时候不会乱套,解决了深层模型训练崩溃的问题,在基础的语言理解、闲聊场景有稳定提升。但在需要多步推理、长上下文记忆、精准逻辑回溯的任务上,比如数学、代码、专业考试、长上下文问答,提升非常有限 。原因正在于它不擅长让模型“精准找回某个早期关键步骤”。
-
AttnRes:兼顾稳定性 + 复杂推理,长上下文 、逻辑题提升碾压
它不仅解决了深层模型的训练稳定性问题,更擅长需要精准回溯、多步推理的高难度任务。
两者在落地适配性上天差地别。
DeepSeek 的 mHC 更像伤筋动骨的大改造,得把现有 AI 的单流架构完全改成多流并行架构,每层都要加新的流处理模块,还要重调全套训练参数,没法直接替换传统残差连接,老模型基本没法直接升级,跟拆房重盖没两样,适配成本极高。
而 Kimi 的 AttnRes 是即插即用的替换件,只需要把模型里原来的残差连接模块换成 Block AttnRes,其他模型结构、训练参数全都不用动,老模型直接升级就能拿到效果提升,就像给房子换个好门锁不用拆墙,适配成本极低。
从已有对比看,Kimi 似乎拿到了更好的“性价比”。
有网友将 Kimi 的 AttnRes 将与 DeepSeek 的 mHC 进行了性能对比,发现在 Kimi 的消融实验中,Kimi 完整无损版本的 Full AttnRes 性能始终优于 mHC,而 Block AttnRes 的性能与之相当,但 Kimi 的方案需要读写的数据量,只有 DeepSeek mHC 的 1/6。
这意味着,在大模型真正走向大规模工程部署的语境下,Kimi 的路线可能具备更强的现实吸引力。
过去十年,Transformer 的大部分创新都集中在注意力、FFN、MoE、位置编码和训练数据上。残差连接则像空气一样存在,重要,但过于基础,以至于几乎没人认真去动它。
而现在,DeepSeek 和 Kimi 先后出手,或许正释放一个信号:当数据红利逐渐到顶,过去的大模型比拼的是“谁能堆更多算力,那么下一代大模型,或许要开始学会“管信息”来拉开差距。
相关文章
