Andrej 看到了一场“编程革命”正在发生。随着 AI 技术的发展,软件编程已经进入了 “3.0 时代”,自然语言取代传统代码成为核心编程接口,大模型则承担起过去需要人工编写的复杂逻辑。
Andrej 指出,这一转变远非简单的工具迭代。当开发者通过日常语言指令即可驱动系统,当用户的需求能直接转化为机器可执行的意图时,我们实际上是在构建一种“新型计算机”。这种计算机不再依赖精确的语法规则,而是以概率化、语义化的方式理解世界——就像人类一样。
这种进化对开发者来说是一件好事,这意味着编程门槛的消弭。对用户来讲更是好事,因为能让交互方式彻底解放,人机协作再也没有语言层面的障碍。正如 Andrej 所强调的:我们正站在人机关系的历史转折点上,未来的软件将不再是冷冰冰的工具,而是能理解、推理甚至主动协作的智能伙伴。这场变革的深度,或许不亚于当年从命令行到图形界面的跨越。
以下内容为 InfoQ 基于 Andrej Karpathy 在现场分享的视频整理而来,在保持原意的基础上进行了编译。
AI 颠覆了传统的软件构件
很高兴今天在这里和大家聊一聊“AI 时代的软件”。我听说在座很多人是本科、硕士、博士等在读学生,正准备进入这个行业。现在正是进入这个行业的一个非常独特、非常有趣的时间节点。
为什么这么说?因为我认为如今的软件正在经历又一次深刻的变革。注意咯,我这里用到的词是 “又一次”,是因为我其实之前就做过类似的演讲,那为啥还要再做这个话题的演讲?因为软件一直在变,所以我也总能找到新材料来做新的演讲。而这一次的变化,我觉得是非常根本性的。
大致来说,软件在过去 70 年里本质上并没有太大改变,但在最近这几年里,它已经经历了两次巨变。因此,我们有大量的工作要做——大量的软件需要被重写或重新设计。
我们把视角转向软件的疆域。如果我们把它(Map of GitHub)视为软件地图的话,它展示了我们所写的所有软件代码,也就是让计算机在数字空间中执行任务的各种指令。
放大之后可以看到,每一个小点其实都是不同的代码仓库,都是已经编写的代码。
几年前我开始意识到,软件正在发生变化,开始出现一种“新的软件类型”。当时我将其称为“软件 2.0”。
软件 1.0,就是我们传统意义上写给计算机的代码。而软件 2.0,本质上是神经网络的权重。你不再直接写代码,而是通过调整数据集、运行优化器,来训练出神经网络的参数。当时神经网络还被很多人当成是像决策树之类的分类器,没什么特别。但我当时的观点是,这其实是一个新的软件范式。
现在在软件 2.0 时代,也开始出现类似“GitHub”的东西。比如 Hugging Face,基本上就是软件 2.0 时代的 GitHub。还有像 Model Atlas 这样的可视化工具,可以看到各种模型的参数——举个例子,中间那个大圆就是图像生成模型 FLUX 的参数点。每次有人基于 FLUX 微调一个新模型,其实就是在这张图上“提交了一次 git commit”,本质上是生成了一个新版本的图像生成器。
所以我们可以理解为:
-
软件 1.0 是写给计算机的代码 -
软件 2.0 是写给神经网络的权重参数
比如 AlexNet,就是一个图像识别神经网络。
过去我们所熟悉的神经网络,大多是“定值函数”型的计算机——比如输入一张图像,输出一个类别标签。但最近发生了一个根本性变化,那就是:神经网络变得可以“被编程”了,这要归功于大语言模型(LLMs)。所以我认为这是一个全新的计算机世界了。
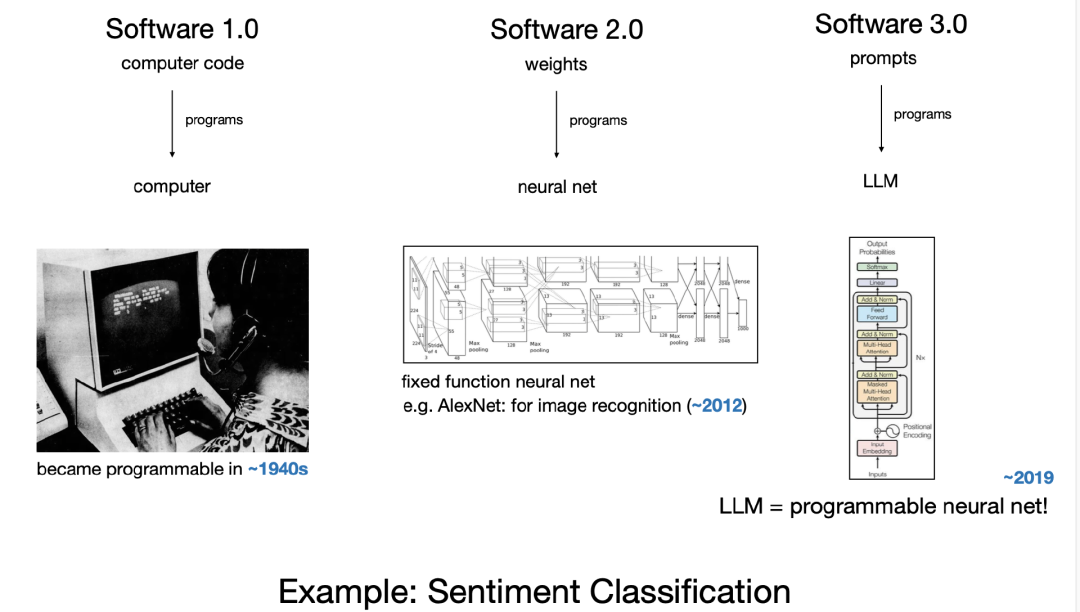
所以这个新时代值得称之为软件 3.0:你不再写代码、不再训练神经网络参数,而是直接通过“Prompt”(提示词)来“编程” LLM。更妙的是,这种程序语言就是我们日常说的 “英语”。
这实在是太有趣了。我们再来用一个例子说明下软件 3.0 时代和其他编程方式的区别:
假设你要做情感分类,在软件 1.0 时代,你需要写一段 Python 代码,到了 2.0 时代需要训练一个神经网络,而现在,很多 GitHub 代码不只是代码了,你可以直接用英语写一个 Prompt 来让大语言模型输出分类结果。

这其实是一种全新的编程方式,而且它是用自然语言完成的。
几年前我意识到这一点时发了一条推文,很多人因此关注到了这一转变。这条推文现在依然是我置顶的内容:我们现在可以用英语来编程计算机了。
我在特斯拉时曾参与自动驾驶系统的开发。我们试图让汽车自动驾驶,并在当时展示过一个架构图。
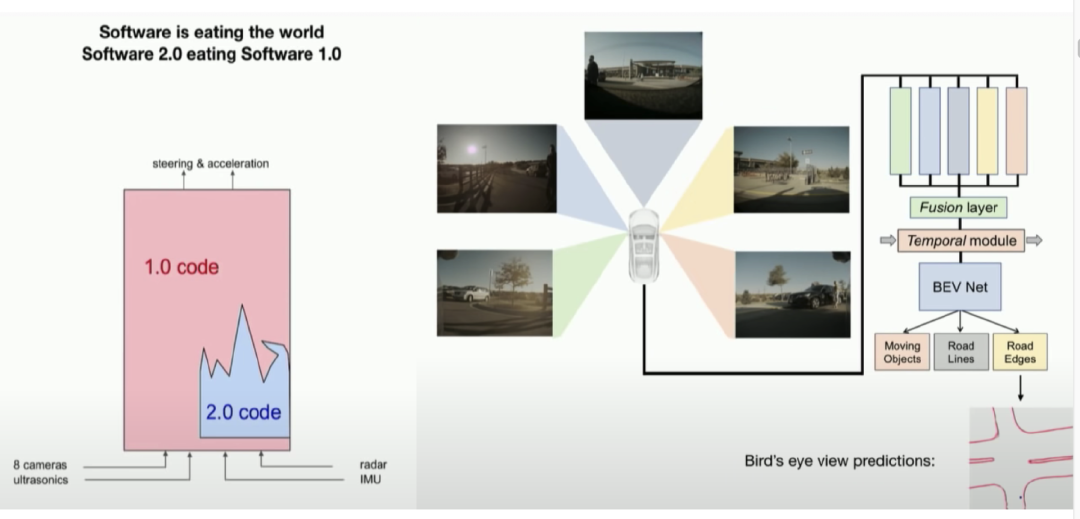
图中显示,输入来自各种传感器(如摄像头),经过一系列软件处理,最终输出方向盘角度和加速度。
当时我指出:系统中有“一吨”左右的 C++ 代码,也就是软件 1.0,同时也开始出现一些神经网络用于图像识别。这种变化非常有趣——随着自动驾驶系统性能提升,神经网络的规模和能力越来越强,同时,我们开始逐步删除大量原本由 C++ 编写的逻辑代码。
原来那些“把多摄像头图像拼接起来”之类的操作,现在交给神经网络来做。结果是:我们 删掉了大量的 1.0 代码。可以说,软件 2.0 堆栈“吞噬”了软件 1.0 堆栈,变成了系统的主干部分。
现在,我们正在经历同样的事情。新的软件范式(软件 3.0)正在快速向整个技术栈渗透。我们现在面前有三种完全不同的编程范式:1.0、2.0、3.0。
如果你正要进入这个行业,我建议你最好对三者都非常熟悉。它们各有优缺点:有的功能可能适合直接写代码(1.0),有的适合训练神经网络(2.0),而有些则只需要写一个 Prompt(3.0)。我们会不断面临这样的抉择:这个功能要用哪种方式实现?要不要训练模型?是不是直接用 LLM 生成答案就可以?
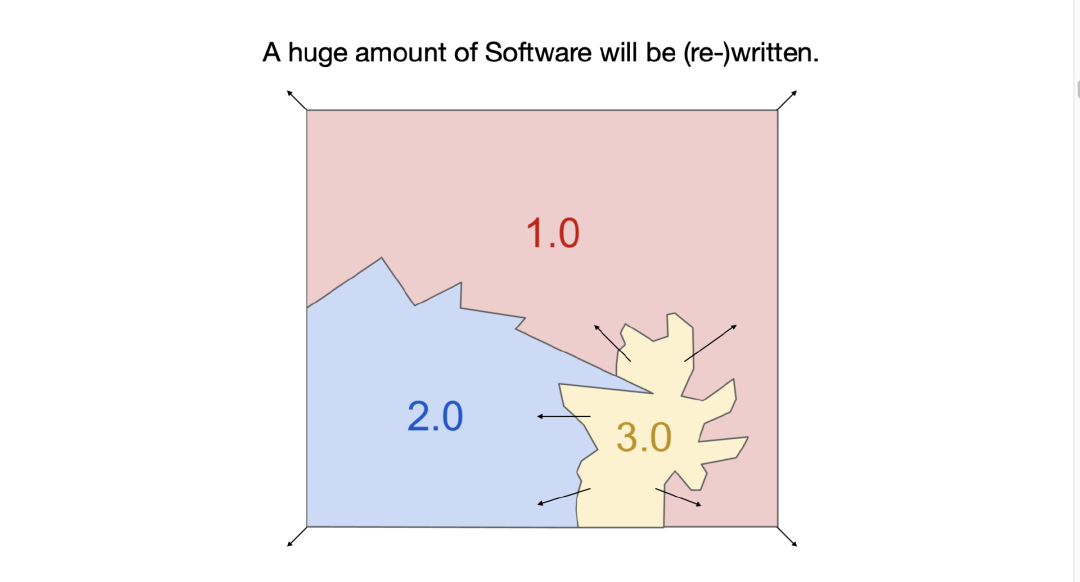
而我们也必须具备在这三种范式之间灵活切换的能力。
接下来,我想进入这场分享的第一部分……
大语言模型(LLM)具备公共基础设施、晶圆厂和操作系统的多重特性——它们正在成为一种新的“操作系统”,由各大实验室打造,并像公用事业一样进行分发(目前是这样)。很多历史类比都适用——在我看来,我们现在的计算水平大概相当于上世纪 60 年代。
关于 LLM,以及如何理解这个新范式和生态系统,以及它的样貌,我想引用一段安德鲁(Andrew)多年前说过的话,他应该接着我后面发言。他当时说:“AI 是新电力。”

我觉得这句话很有启发性,它确实很好地捕捉到了一个关键点:LLM 显然具备类似“公用事业”的属性。
现在的 LLM 实验室,比如 OpenAI、Gemini、Anthropic 等,会投入大量资本支出(CapEx)去训练 LLM,这就像在建设电力网络。而随后,它们又需要通过 API 把智能能力“供电”给我们所有人,这是运营支出(OpEx)。我们通过按百万 token 计价的方式进行付费接入。这种模式本质上就像对公用事业的需求:我们要求低延迟、高可用、服务质量稳定。
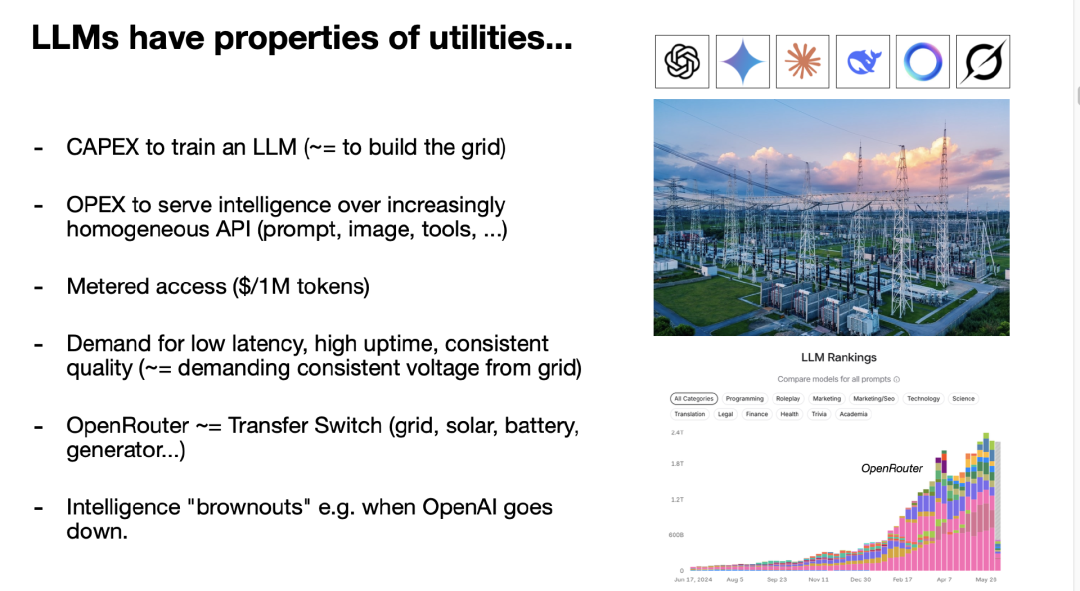
在电力系统中,有“切换开关”,可以在市电、太阳能、电池或发电机之间切换。在 LLM 世界里,我们也有“开放路由器”类的机制,可以轻松在多个 LLM 提供方之间切换。因为 LLM 是软件,它们不会在物理空间上产生直接竞争,你可以同时使用多个“供电方”。这点很有趣。
前几天我们看到多个 LLM 出现故障,人们突然无法正常工作了。我们逐渐依赖它们到这样一个程度:一旦最先进的 LLM “宕机”,就像发生了“智能停电”,就像电网电压不稳定时整个社会变“笨”了。我们越依赖这些模型,这种影响只会越发明显。

但 LLM 不只是具有“公用事业”的属性,它们也有点像“晶圆厂”。训练 LLM 需要的资本支出是巨大的,这不仅仅是造个发电站那么简单。这是一项高强度的研发投资。LLM 技术栈复杂而深,技术秘密正在快速集中在少数几个实验室中。
不过类比也开始模糊了,因为毕竟 LLM 是软件,而软件的可变性很强、防御性较弱。不过还是可以找到一些对应关系。例如,可以将“4nm 工艺制程”类比为一个具有固定 FLOPS 上限的 GPU 集群。当你仅使用 Nvidia GPU 做模型训练、而不涉足芯片制造时,这是类似“无晶圆厂”的模式;而如果你像 Google 一样自己设计 TPU 并训练模型,那就是“英特尔模式”——你拥有自己的“晶圆厂”。
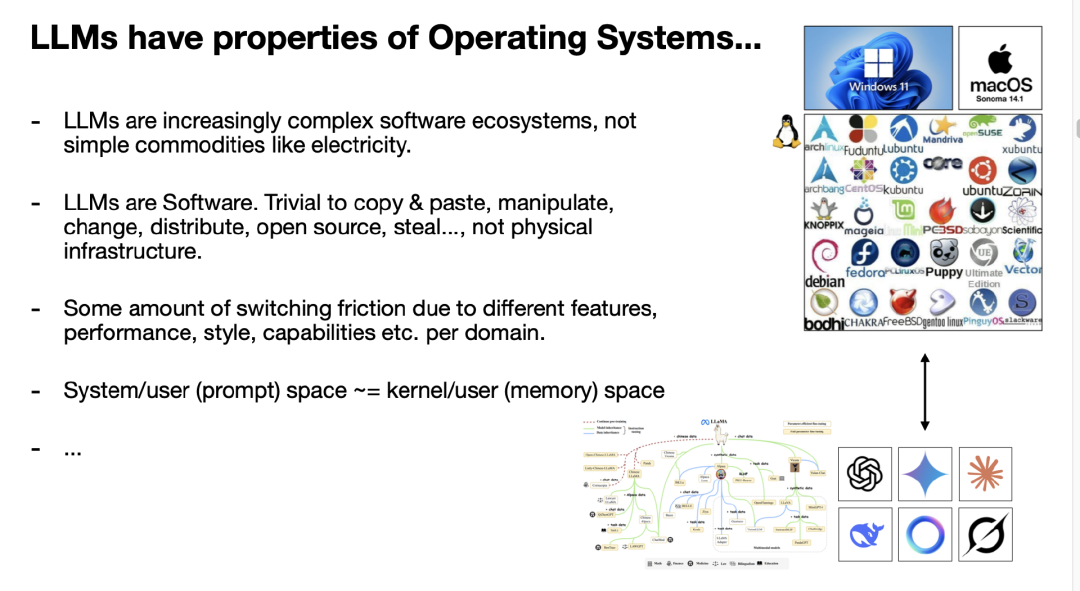
但对我来说,最贴切的类比其实是:LLM 像操作系统。这不仅仅是电力或水这种从水龙头流出的商品,而是越来越复杂的软件生态系统。
但 LLM 不只是具有“公用事业”的属性,它们也有点像“晶圆厂”。训练 LLM 需要的资本支出是巨大的,这不仅仅是造个发电站那么简单。这是一项高强度的研发投资。LLM 技术栈复杂而深,技术秘密正在快速集中在少数几个实验室中。
不过类比也开始模糊了,因为毕竟 LLM 是软件,而软件的可变性很强、防御性较弱。不过还是可以找到一些对应关系。例如,可以将“4nm 工艺制程”类比为一个具有固定 FLOPS 上限的 GPU 集群。当你仅使用 Nvidia GPU 做模型训练、而不涉足芯片制造时,这是类似“无晶圆厂”的模式;而如果你像 Google 一样自己设计 TPU 并训练模型,那就是“英特尔模式”——你拥有自己的“晶圆厂”。
但对我来说,最贴切的类比其实是:LLM 像操作系统。这不仅仅是电力或水这种从水龙头流出的商品,而是越来越复杂的软件生态系统。
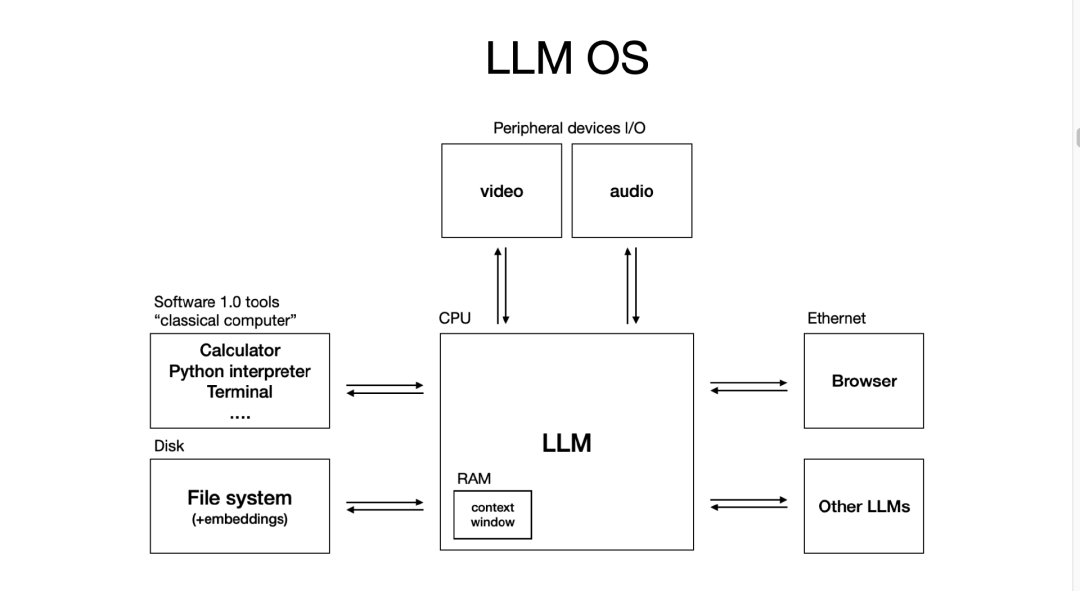
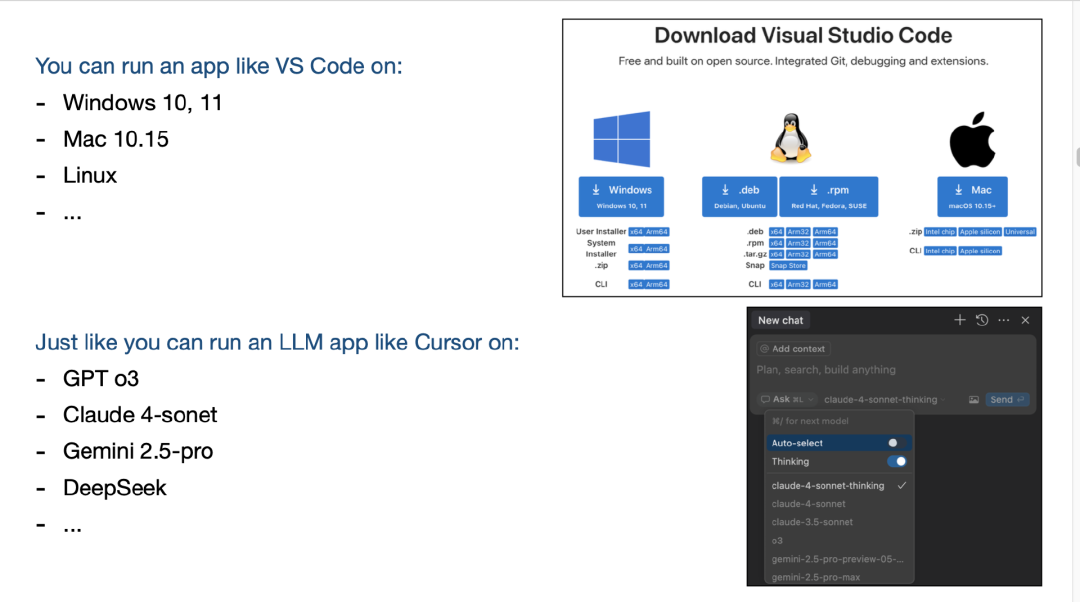
再举个例子,比如你想下载一个应用程序,比如 VS Code。你可以在 Windows、Linux 或 macOS 上运行它。同样地,现在你可以拿一个 LLM 应用,比如 Cursor,在 GPT、Claude 或 Gemini 上运行——只需要一个下拉选择而已,这非常类似。
还有更多类比浮现在我脑海中。我们现在所处的阶段,就像是 1960 年代初期——LLM 所需的计算资源还非常昂贵,这使得模型必须集中部署在云端,我们只能作为“瘦客户端”通过网络接入这些计算机。每个人都没有完整控制权,因此我们只能“时间共享”地使用它们——就像当年云端计算机的批处理模式。

那时候的操作系统也是集中部署的,一切都需要网络传输,大家排队等待自己的“批次”被执行。个人计算机革命还未发生——因为经济上还不合理。但现在已经有人在尝试了,比如 Mac Mini 实际上很适合跑某些 LLM 模型。因为很多 LLM 推理是“batch=1”的,非常依赖内存,而 Mac Mini 恰好内存大,这可能是个人计算机化的早期迹象。

不过现在还没人真正发明“LLM 的 GUI”。我每次跟 ChatGPT 或其他模型交流时,都感觉像是在用终端和操作系统交互——纯文本接口,直接对话。我们现在看到一些 app 拥有 GUI,但还没有一个“跨任务通用 GUI”出现。这是一个还没被发明出来的机会。
LLM 与传统操作系统还有一个重大区别,这点让我特别在意:LLM 颠覆了科技扩散的路径。
历史上每一项革命性技术——电力、密码学、计算、飞行、互联网、GPS ——最早的使用者总是政府或大型企业,因为新技术贵又复杂。然后才逐渐扩散到消费者。
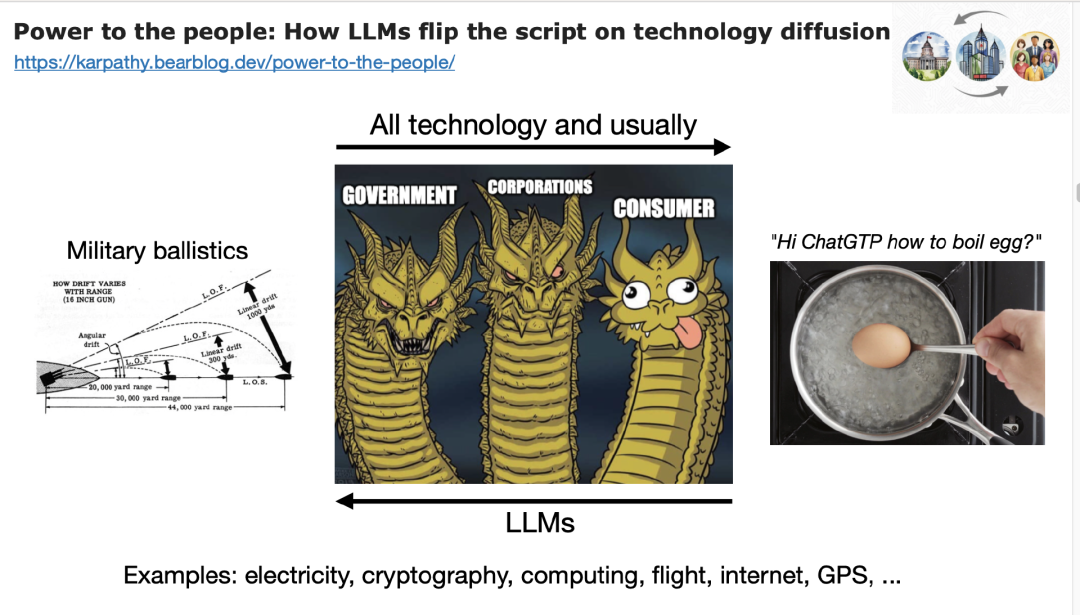
但 LLM 正好相反。最早的应用者是我们这些普通用户。例如,过去早期计算机用于军用弹道学,但现在 LLM 却在教我怎么煮鸡蛋!我每天的大部分使用就是如此。新的“魔法计算机”现在首先服务的是普通人,而不是国家或企业。
政府和企业反而在落后地采用这些技术。这完全颠倒了传统路径,也可能启示我们:真正的 killer app 会从个人用户端长出来。
总结一下:LLM 实验室和 LLM 这两个术语现在非常准确。但我们需要意识到,LLM 本质上是复杂的软件操作系统,我们正在“重新发明计算”,就像 1960 年代那样。而且它们现在以“时间共享”的方式提供服务,像公用事业一样被分发。

真正不同的是,它们不是掌握在政府或少数企业手里,而是属于我们每一个人。我们每个人都有电脑,而 LLM 只是软件,它可以在一夜之间传遍整个星球,进入数十亿人的设备。
这是疯狂的。它已经发生了。现在,轮到我们进入这个行业,去编程这个“新计算机”。
太不可思议了。
大模型有超能力,也有认知缺陷
要编程 LLM,我们必须先花点时间思考这些东西到底是什么。我尤其喜欢谈谈它们的“心理学”。
我喜欢把 LLM 想象成“人类精神”(people spirits)。它们是对人类的随机模拟(stochastic simulation),而这个模拟器恰好是一个自回归 Transformer。Transformer 是一种神经网络,它在 token 层面上工作,逐块处理,就像“咔哒、咔哒、咔哒”一样,每一块的计算量几乎是一样的。

这个模拟器的本质是某些权重参数,它被拟合到了我们从互联网上获得的所有文本上。于是我们得到了这样一个模拟器。由于它是用人类的数据训练出来的,所以它具备一种“涌现”的类似人类的心理学特征。
你首先会注意到的一点是,LLM 具有百科全书式的知识和记忆力。它们可以记住非常多的信息,远远超过任何一个人能记住的量。因为它们读过的东西太多了。这让我想起一部电影《雨人》(Rainman),我真的很推荐大家去看一下,非常棒的一部电影。我非常喜欢这部电影。达斯汀·霍夫曼在里面饰演一个自闭症学者型天才,他拥有近乎完美的记忆力。他能看一遍电话簿,然后就记住所有的名字和电话号码。
我觉得 LLM 在某种意义上就很像这样,它们可以轻松记住 SHA 哈希值、各种信息等。
所以在某些方面,它们无疑有“超能力”。但它们同样也存在很多“认知缺陷”。例如,它们经常“幻觉”(hallucinate),也就是说,它们会凭空编造内容。它们对于自身知识的内部模型也不够好,至少还不够完善。虽然这方面已经有所进步,但仍然不够完美。
它们展现出的是一种“锯齿状的智能”:在某些领域,它们可以展现出超人的问题解决能力,但在其他方面却会犯下人类绝不会犯的错误。例如,它们可能坚持说 9.11 比 9.9 大,或者说“strawberry”里有两个 “R”。这些都是比较有名的例子。这些“棱角”是你很容易会被绊倒的。
它们还会“顺行性遗忘”(Anterograde Amnesia),我这里指的是:如果你有一个新同事加入团队,他会随着时间推移慢慢了解组织、获取上下文、增长知识,他会回家睡觉、巩固知识、发展专长。但 LLM 不会自动做到这些。这其实是目前 LLM 的研发还没有解决的问题。
所以,LLM 的上下文窗口其实更像是“工作记忆”。你必须非常明确地对其进行编程,因为它不会像人类一样“自然而然”变得更聪明。我觉得很多人会在这个类比上误入歧途。
我推荐大家看两部电影:《记忆碎片》(Memento)和《初恋 50 次》(50 First Dates)。在这两部电影中,主角的大脑权重是“固定的”,而上下文窗口每天早上都会被清空。这样一来,要去上班、要维持人际关系就非常困难。而这正是我们每天与 LLM 打交道时经常遇到的情形
还有一点值得一提,是跟安全相关的 LLM 使用限制。比如说,LLM 非常容易“轻信”外界信息,它们容易受到提示注入(prompt injection)攻击的影响,可能会泄露你的数据等等。当然,还有很多其他安全方面的考量。
大模型带来的机遇
那么现在的问题在于:我们该如何编程这些系统?我们该如何在避开它们局限的同时,发挥它们的超能力?
接下来我想讲的,是如何实际使用这些模型,以及其中存在的一些最大机会……
大型语言模型(LLMs)就像“人的灵魂”,这意味着我们可以用它们构建具备部分自主能力的产品。
我整理了一些在这次分享中觉得有趣的点,首先我最感兴趣的是所谓的“部分自主应用”。
比如,以编程为例,你当然可以直接去用 ChatGPT,复制粘贴代码,提交 bug 报告,获取回复,再继续复制粘贴。但为什么要这样做?为什么要直接跟操作系统交互?其实更合理的方式,是为这个场景构建一个专门的应用。
我想在座很多人可能都在用 Cursor,我自己也在用。Cursor 就是一个很好的例子,它比直接去用 ChatGPT 更合适。它是早期的 LLM 应用中非常典型的一种,具备一些我认为在所有 LLM 应用中都非常有用的共性:
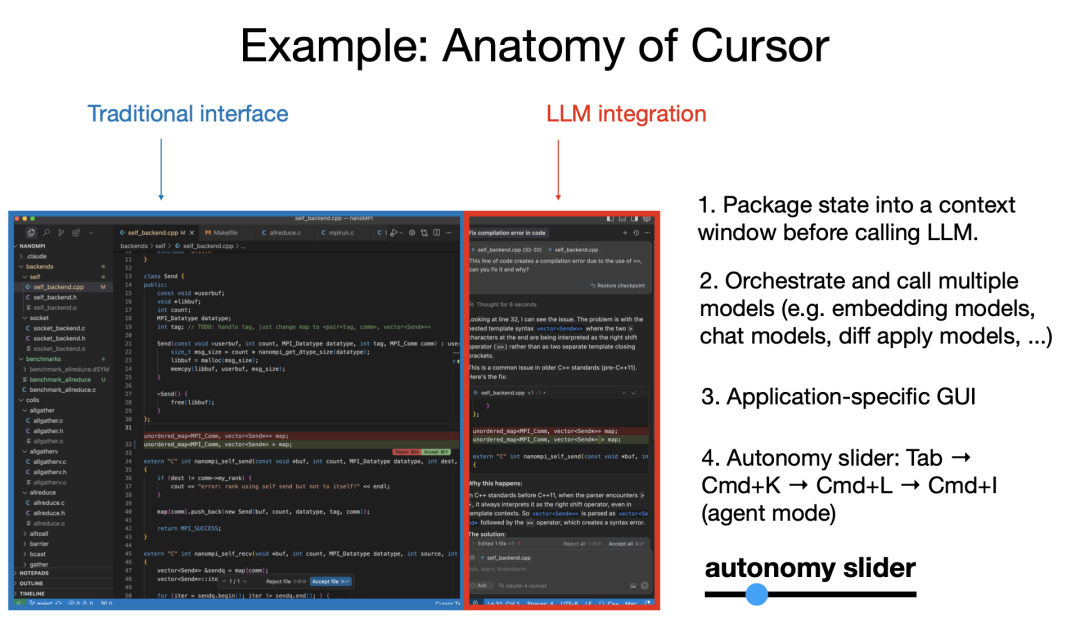
首先,它保留了传统的交互界面,人类依然可以手动完成所有工作,但在此基础上,它集成了 LLM,可以处理更大块的任务。
一些共性的关键点包括:
- 上下文管理:LLM 在应用中自动处理大量上下文管理任务;
- 多轮调用编排:比如在 Cursor 中,底层有用于代码文件的嵌入模型、聊天模型、diff 应用模型等,它们都经过编排协调;
- 专用 GUI 的重要性:我们并不总是希望用纯文本交互,文本不易读、不易理解,而且很多操作也不适合用文本完成。你更希望看到一个 diff,用绿色表示新增、红色表示删除,然后只需 Command + Y 接受、Command + N 拒绝,而不是用文本输入这些命令。GUI 让我们可以快速审查这些不完美的系统,效率更高。
我后面会再讲到这一点。再提一个关键特性,就是我所谓的“自主滑块”(autonomy slider)。以 Cursor 为例,你可以选择轻量的补全(你主导),或者选中一段代码 Command + K 修改它,再比如 Command + L 改整个文件,甚至 Command + I 任意改整个 repo。这就是“自主滑块”:你可以根据任务复杂度,选择愿意放权给 LLM 的程度。
再看一个成功的 LLM 应用例子——Perplexity。

它跟 Cursor 类似,具备如下特性:
-
集成了大量信息处理; -
编排了多个 LLM 调用; -
提供 GUI 来让你审阅生成结果,比如引用来源你可以点进去看; -
也有“自主滑块”:你可以只做一次快速搜索,或者进行深度研究,甚至查完 10 分钟后再回来。这些都是你放权的不同层级。
所以问题来了:我认为未来大量软件都会变成“部分自主”的,那么这些软件会是什么样子?对于你们这些维护产品和服务的人来说,怎么把自己的产品做成“部分自主”的?LLM 是否能看到人能看到的所有内容?是否能执行人类能执行的所有操作?人是否能始终保持在环中进行监督?因为这些系统仍然容易出错,尚未完美。
我们还得思考:在像 Photoshop 这样的图形软件里,diff 应该如何呈现?传统软件界面里,很多开关、控件都是为人设计的,现在这些也必须要能被 LLM 理解和访问。
关于 LLM 应用,还有一点我认为没有被充分重视:我们和 AI 的协作形式正在发生变化。通常 AI 负责生成,我们负责验证。而我们要让这个生成 – 验证循环尽可能快,这样我们才能高效地完成工作。
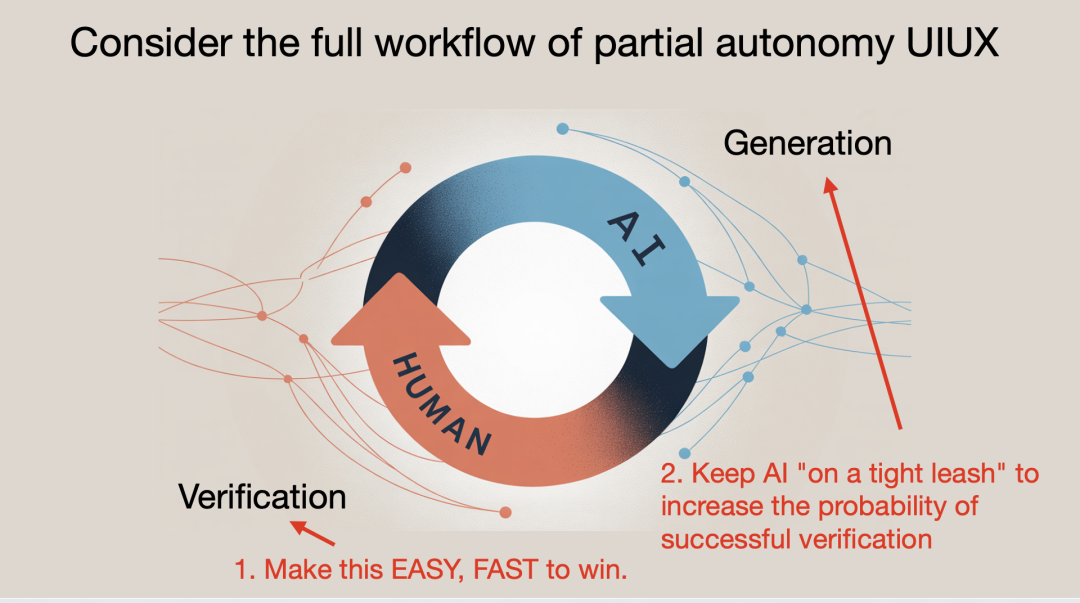
让这个循环更快的两个核心方向:
- 加快验证速度:GUI 非常重要。GUI 利用了我们大脑里的视觉 GPU——读文本很费劲,看图很快。可视化能极大提高系统审阅效率;
- 控制 AI 行为的范围(“牵好绳子”):现在很多人对 AI Agent 太激动了。但你看,比如一次性给我生成一个包含 1 万行代码的 diff 并不实用。我作为人类仍然是瓶颈,我必须确认没有引入 bug、逻辑正确、安全无虞等等。所以必须控制 AI 的主动程度。
- 我现在做 AI 辅助编程的时候,就是这个感觉:小的字节级补全很顺,但如果让我用一个过于激进的 Agent 来完成任务,那体验就不太好了。
我自己还在探索怎么把这些 Agent 融入我的编程流程,实践 AI 辅助编程。我倾向于以小步快跑的方式前进,确保每次修改都是安全的,这样可以让验证 – 生成循环非常快。

- 我也看到很多人分享了关于如何和 LLM 配合的最佳实践。举个例子:如果你的 prompt 很模糊,AI 就容易跑偏,验证失败后你还得重新 prompt,这就拖慢节奏。更好的方式是,在 prompt 上多花点时间,明确具体目标,提高验证成功率,让流程更顺。
- 对我来说,这应该是两个不同的应用:一个是给教师设计课程的工具,一个是面向学生的授课工具。它们之间会产生一个“课程”这个中间产物,是可审阅的,可以确保结构合理、内容一致。这种方式把 AI 控制在教学大纲、项目节奏范围内,更容易成功。
我还有一个类比想提一下:其实我对“部分自主”不陌生,我在 Tesla 做了五年,这就是个“部分自主产品”。例如,Autopilot 的 GUI 就直接嵌在仪表盘里,展示神经网络看到的内容;我们也有“自主滑块”:随着时间推进,Autopilot 能执行的任务越来越多。
氛围编码:是计算机,也具备人的特质
接下来我想换一个话题,谈谈另一个特别的维度——不仅是新的编程方式出现了,而且这个“新语言”是用英语来编程。
也就是说,所有人都可以编程了,因为大家都讲自然语言。这让我极度看好这个方向,因为这在历史上是前所未有的。
过去你得花 5 到 10 年学习编程,现在不再需要了。
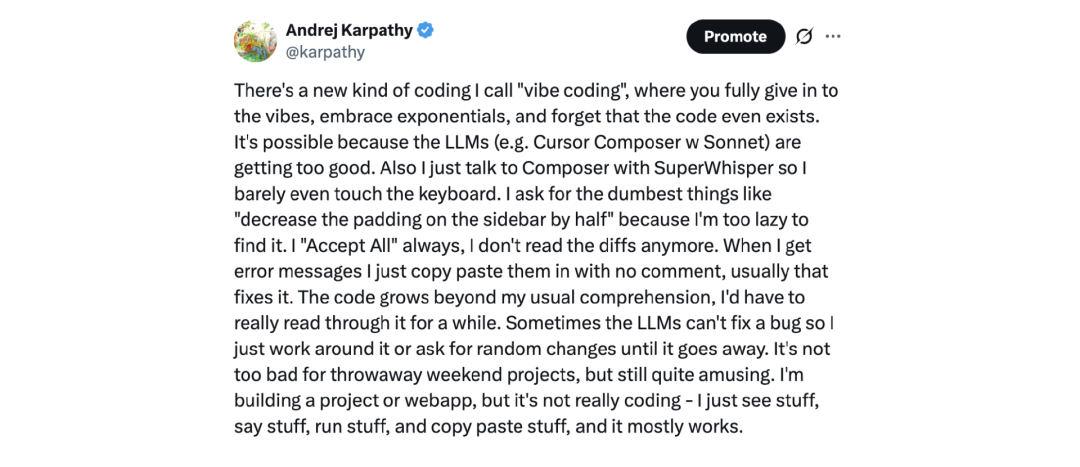
你有没有听说过 “vibe coding”?这个概念最早是从我发的一个推文火起来的。
过去你得花 5 到 10 年学习编程,现在不再需要了。你有没有听说过 “vibe coding”?这个概念最早是从我发的一个推文火起来的。
过去你得花 5 到 10 年学习编程,现在不再需要了。你有没有听说过 “vibe coding”?这个概念最早是从我发的一个推文火起来的。
我觉得这将成为一代人接触软件开发的“网关药物”。我不是“末世论者”,我很看好下一代人。我也尝试过 Vibe Coding,因为它真的太有趣了。
Vibe Coding 特别适合那种“周六随便搞点啥”的场景,比如我之前就用它构建了一个 iOS 应用……
- 大型语言模型(LLM)如今已经成为数字信息的主要消费者和操作者之一(在图形用户界面 / 人类和 API/ 程序之外),所以我们要为 Agent 而构建!

 过去你得花 5 到 10 年学习编程,现在不再需要了。
过去你得花 5 到 10 年学习编程,现在不再需要了。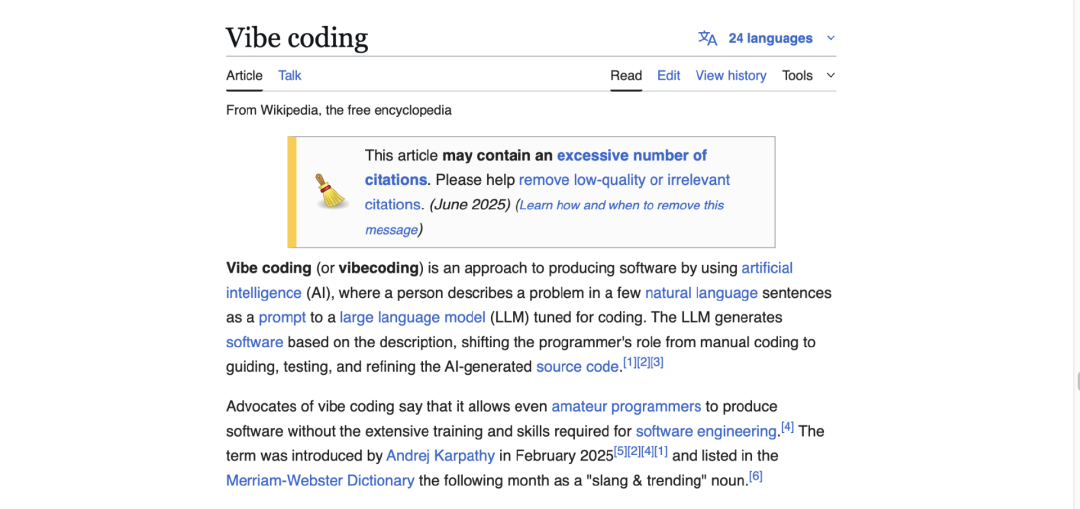 过去你得花 5 到 10 年学习编程,现在不再需要了。
过去你得花 5 到 10 年学习编程,现在不再需要了。相关文章
